Gender Inference from Character Sequences in Multinational First Names
Note: This post has also been published on Medium Towards Data Science.
Consider the names “John” and “Cindy” — most people would instantly mark John as a male name and Cindy as a female one. Is this the case primarily because we have seen so many examples of male Johns and female Cindys that our brains have built up a latent association between the specific name and the corresponding gender? Probably.
But some component of the name itself (its spelling / combination of letters) contributes to the gender with which it is associated to a large degree as well. Consider the names “Andy” and “Andi.” They are phonetically identical (/ˈæn.di/), however most people would categorize “Andy” as male and “Andi” as female upon seeing the spellings. The suffix of a name can indicate the name’s gender; however, the rules are not cut and dry. For example, names “ending in -yn appear to be predominantly female, despite the fact that names ending in -n tend to be male; and names ending in -ch are usually male, even though names that end in -h tend to be female.” 1 There are many more character patterns that correspond to a certain gender classification than just the suffix — this task is not trivial.
The gender classification of a name becomes increasingly difficult when you consider the space of all names from around the world — the examples I have given thus far are admittedly from a standard American viewpoint. Let’s now consider two Indian names (a culture with which I have next to no exposure): when I see the names “Priyanka” and “Srikanth,” I instantly assume Priyanka to be female and Srikanth to be male. Why is that? How do our brains extract the gender revealing information encoded in the sequence of characters that compose a name?
Who cares?
Accurate prediction of an unknown individual’s gender is desirable for use in marketing, social science, and many other applications in academia and industry. Perhaps the most obvious and telling indicator of a person’s gender is their first name. Most previous work in classifying gender via first name has concerned using a large corpus of known names to give a probabilistic prediction on the names that are known. This post attempts to explore the space of names that are unknown by examining the facets of a first name — specifically focusing on the sequences of characters within the name — that contain non-trivial gender-revealing information. It is also an exercise in applying ML/DL to real problems.
This gender classification problem is similar to but fundamentally different from a larger class of problem in Natural Language Understanding. Given the words “cat” and “dog,” almost all people will assign cat to female and dog to male.

The core difference here is that when we read the word “dog,” our brains translate the sequence of characters “d-o-g” to a high dimensional representation of the abstract entity that is our understanding of a dog. It is some combination of features in this high dimensional representation in our brains that correlate more closely to our abstract representation of males than to that of females; it is not the sequence of characters themselves that contain the gender-revealing information (at least for the most part).
Our gender classification problem becomes even more interesting when you abstract it from names to all words in general. Linguistically, many languages are structured with the concept of a grammatical gender wherein classes of nouns in the language are formally associated with one of a discrete set of genders.2 In such languages, certain sequences of characters in a word can almost surely identify the grammatical gender of the word. Learning these character sequences — whether explicitly or implicitly — is an inherent part of learning the language. Furthermore, understanding of such character patterns may assist in understanding of unseen words. For these reasons, studying information embedded in character sequences seems like an interesting and integral topic to Linguistics and NLU that is beyond the scope of this post.
Methodology
All code for this project is available at
Naïve-Bayes
As an initial approach to the topic, I explore a vanilla machine learning technique using hard-coding features of names that are known to have high correlation to the name’s associated gender (such as suffix, as mentioned earlier). This quick and dirty implementation is actually able to achieve pretty good results with minimal work.
The features in used in this approach are pulled directly from the NLTK book: Names ending in -a, -e and -i are likely to be female, while names ending in -k, -o, -r, -s and -t are likely to be male… names ending in -yn appear to be predominantly female, despite the fact that names ending in -n tend to be male; and names ending in -ch are usually male, even though names that end in -h tend to be female.1
def gender_features(name):
features = {}
features["last_letter"] = name[-1].lower()
features["first_letter"] = name[0].lower() # names ending in -yn are mostly female, names ending in -ch are mostly male, so add 3 more features
features["suffix2"] = name[-2:]
features["suffix3"] = name[-3:]
features["suffix4"] = name[-4:]
return featuresThese features are plugged into the NLTK NaiveBayesClassifier for easy training and testing.
Results
I trained this model with a 70/30 train-test split (~95k training names, ~40.6k testing names). The testing accuracy was around 85%, which is arguably pretty good for this task.
Example code usage is available at naive_bayes/demo.ipynb.
Char-RNN
Of course, there are many many patterns of characters in a name that might contain gender cues — especially when considering our global (worldly) name space; it seems absurd to attempt to hard code every possible pattern when we have Deep Learning. In this vein, I explore a Character-level Recurrent Neural Network approach using PyTorch that attempts to learn the various gender-revealing sequences without having to explicitly specify them.
Tensor Representation
The first step here is to figure out how to represent a name as a tensor. Since our goal is to pick up on all of the nuances in the sequences of letters that make up first names, we want to break up the name and look character by character. In order to represent each character, we create a one-hot vector of size <1 x N_LETTERS> (a one-hot vector is filled with 0s except for a 1 at the index of the current letter, e.g. "c" = <0 0 1 0 0 ... 0>).
def name_to_tensor(name, cuda=False):
"""converts a name to a vectorized numerical input for use with a nn
each character is converted to a one hot (n, 1, 26) tensor
Args:
name (string): first name (e.g., "Ellis")
Return:
tensor (torch.tensor)
"""
name = clean_str(name)
tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
torch.zeros(len(name), N_LETTERS, out=tensor)
for li, letter in enumerate(name):
letter_index = ALL_LETTERS.find(letter)
tensor[li][letter_index] = 1
return tensordef tensor_to_name(name_tensor):
"""converts a name tensor to a string representation of a name
Args:
tensor (torch.tensor)
Return:
name (string)
"""
ret = ""
for letter_tensor in name_tensor.split(1):
nz = letter_tensor.data.nonzero()
if torch.numel(nz) != 0:
ret += (string.ascii_lowercase[nz[0, 1]])
return retName/Tensor conversion
An alternative approach might be to store the value of a character by its location in the alphabet "c" = 3; however, this might cause the model to learn some patterns in the value of the character that we do not intend (e.g., it might learn that “c” is more similar to “a” than it is to “x” because they are closer alphabetically while there is actually no similarity difference).
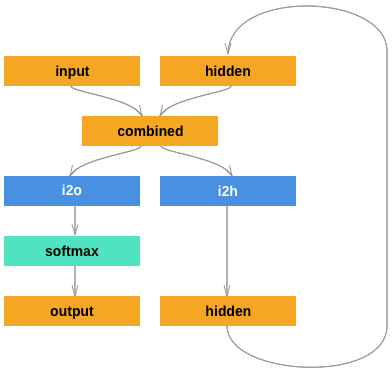
Model Definition
We then define the structure of the network module itself:
Following the direction of the PyTorch name nationality classification example, we create a simple network with 2 linear layers operating on an input and hidden state, and a LogSoftmax layer on the output. I use 128 hidden units.3
This is a very simple network definition, and likely could be improved by adding more linear layers or better shaping the network.
class RNN(nn.Module):
"""Recurrent Neural Network
original source: https://goo.gl/12wiKB
Simple implementation of an RNN with two linear layers and a LogSoftmax
layer on the output
Args:
input_size: (int) size of data
hidden_size: (int) number of hidden units
output_size: (int) size of output
"""
def **init**(self, input_size, hidden_size, output_size):
super(RNN, self).**init**()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
combined = torch.cat((input.float(), hidden), 1)
hidden = self.i2h(combined)
output = self.i2o(combined)
output = self.softmax(output)
return output, hidden
def init_hidden(self, cuda=False):
ret = torch.zeros(1, self.hidden_size)
if cuda:
ret.cuda()
return Variable(ret)Results
I again split the dataset with a 70/30 train-test split (~95k training names, ~40.6k testing names). The best testing accuracy I was able to achieve was around 75.4% accuracy. I did not spend much time tweaking hyper-parameters for better results.
Dataset — name2gender/data/
I have extended NLTK’s names corpus with many more datasets representing various cultures into a large dataset (~135k instances) of gender-labeled first names, which is available on my repository. See data/dataset.ipynb for further information on how I pulled it together. Note: I did not spend a ton of time going through and pruning this dataset, so it is probably not amazing or particularly clean (I would greatly appreciate any PR’s if anyone cares or has the time!).
Improving / cleaning this dataset would likely be the most impactful improvement initially. Additionally, using a dataset of only names from a single culture would likely be much better at predicting names in that culture.
Disclaimer
It is worthy to acknowledge that there are many names, such as my own (Ellis), that are about equally common among both genders. Datasets containing discrete labels, as opposed to frequency of occurrence in the world, were much easier to come across, and so I have only taken into consideration the binary classification of names given by these datasets. A more robust approach would incorporate the frequency of occurrence in a population to give a more probabilistic gender prediction. The “Gender-name association scores” approach by Wendy Liu might be a good approach.4 The presence of gender ambiguous names also limits the best case real-world accuracy that could be achieved by a gender classification system.
Furthermore, there are increasing movements being made to recognize more than the traditional binary male and female genders in our society. As these efforts are still in their infancy and there is very little (if any) data containing these expanded gender classifications, I make no attempt to incorporate them into this analysis.
I also only take names written in the Latin Alphabet into consideration. Abstracting to entirely language agnostic classification is too formidable a task for the sake of this post.
Future Work
As I touched on above, improving the dataset is definitely the best starting point for improvements. Application of this name to gender classification to variations of first names would be a really useful to anyone who finds first name classification useful. As Wendy Liu puts it:
“Nicknames, abbreviations, mangled names, and usernames can frequently contain non-trivial gender cues. Identifying strategies for extracting and using these cues to more accurately infer gender is a promising direction for future work.” 4
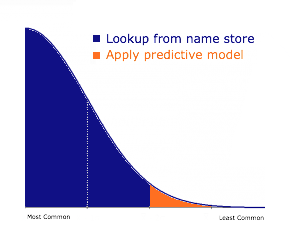
There is also the possibility of crafting the testing scheme to better represent a real world use case. In my analysis, I treated every name as equally likely to occur. A better real world dataset might include some representation of how frequently a certain name occurs in the world. For example, “John” would have a much higher frequency rating than “Ellis.” This change would affect how the testing results are calculated, and the system as a whole. We would ideally have most of the common first names included in our dataset.
For such names, we could simply lookup what our datastore has for the gender of the name. Our predictive system would then only be applied to the set of names that are not common. To test this system setup, we could sort the names by frequency rating, and leave the 30% of names that are least common for the test set.
References
-
Bird, S., Klein, E., and Loper, E. “6.1.1 Gender Identification.” Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit, O’Reilly, 2009, https://www.nltk.org/book/ch06.html. ↩ ↩2
-
“Grammatical Gender.” Wikipedia, Wikimedia Foundation, 21 Dec. 2017, http://en.wikipedia.org/wiki/Grammatical_gender. ↩
-
Robertson, S. “Classifying Names with a Character-Level RNN.” Classifying Names with a Character-Level RNN, PyTorch Docs, 2017, http://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html. ↩
-
Liu, W., and Ruths, D. “What’s in a Name? Using First Names as Features for Gender Inference in Twitter” AAAI Spring Symposium Series (2013), 21 Dec. 2017, link. ↩ ↩2