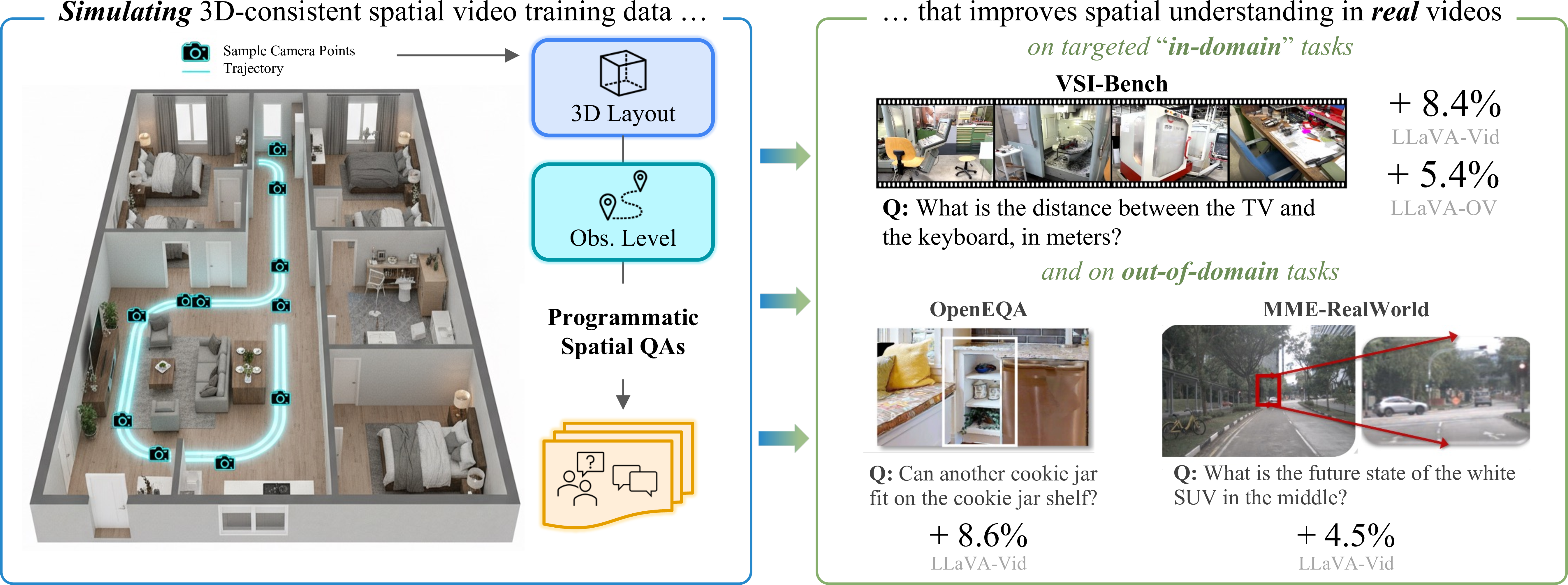
SIMS-V: Simulated Instruction-Tuning for Spatial Video Understanding
Leveraging 3D simulators to create spatially-rich video training data that improves real-world spatial understanding in MLLMs.
Abstract
Despite impressive high-level video comprehension, multimodal language models struggle with spatial reasoning across time and space. While current spatial training approaches rely on real-world video data, obtaining diverse footage with precise spatial annotations remains a bottleneck. To alleviate this bottleneck, we present SIMS-V—a systematic data-generation framework that leverages the privileged information of 3D simulators to create spatially-rich video training data for multimodal language models. Using this framework, we investigate which properties of simulated data drive effective real-world transfer through systematic ablations of question types, mixes, and scales. We identify a minimal set of three question categories (metric measurement, perspective-dependent reasoning, and temporal tracking) that prove most effective for developing transferable spatial intelligence, outperforming comprehensive coverage despite using fewer question types. These insights enable highly efficient training: our 7B-parameter video LLM fine-tuned on just 25K simulated examples outperforms the larger 72B baseline and achieves competitive performance with proprietary models on rigorous real-world spatial reasoning benchmarks. Our approach demonstrates robust generalization, maintaining performance on general video understanding while showing substantial improvements on embodied and real-world spatial tasks.
Why Simulation?
Spatial reasoning requires precise 3D annotations—exact distances, relative positions, and spatial configurations across time. While this information is critical for training video language models, obtaining it from real-world footage presents significant challenges. Manual annotation of precise 3D spatial relationships requires expert knowledge and is prohibitively costly at scale. Depth sensors and SLAM systems provide only noisy approximations, not perfect ground truth. Moreover, real-world datasets are inherently constrained by physical locations and recording resources.
Simulators offer a uniquely powerful alternative by providing: (1) perfect ground truth with exact 3D positions and spatial relationships for every object at every frame; (2) privileged information enabling access to complete scene layouts beyond what’s visible in the camera view; (3) systematic control over trajectories and scenes to ensure comprehensive spatial coverage; and (4) scalable generation at minimal cost—we created 200K+ question-answer pairs across 2.5K diverse video trajectories.
The key question we investigate is: Which properties of simulated spatial data enable effective transfer to real-world video understanding? Our systematic experiments reveal that training on just 25K carefully designed simulated examples achieves competitive performance with large proprietary models on real-world benchmarks.
The SIMS-V Pipeline
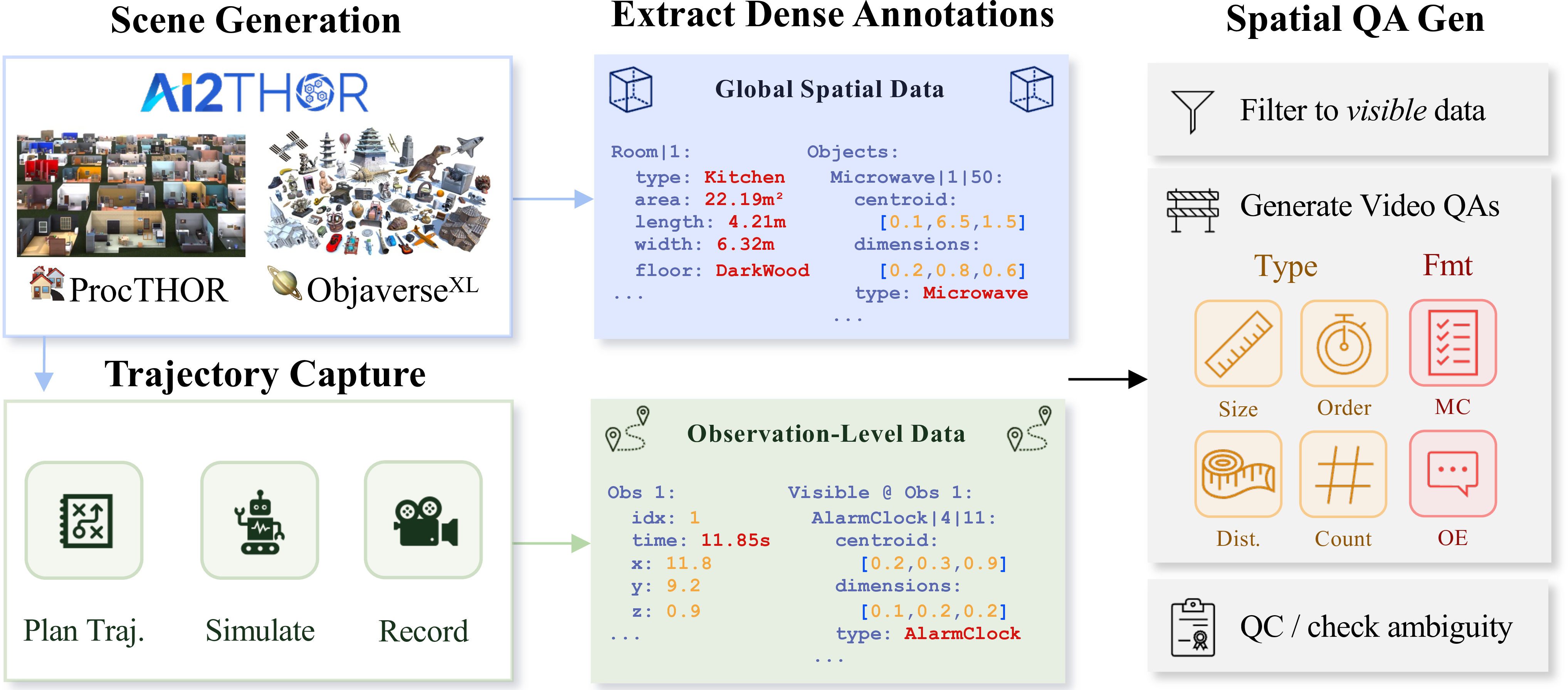
SIMS-V is a simulated instruction-tuning framework for multimodal spatial video understanding. Our systematic pipeline (Figure 2) leverages procedurally generated 3D environments from AI2-THOR, ProcTHOR, and Objaverse to programmatically create rich question-answer pairs about spatial configurations across videos.
The pipeline extracts two complementary types of metadata: (1) observation-level data including per-frame visible objects, instance segmentation masks, and agent position; and (2) global spatial data including complete room layouts and 3D object positions. This privileged information enables us to generate questions that require reasoning about spatial relationships beyond what’s immediately visible—for instance, asking about object locations encountered earlier in the video or metric distances between objects. Using this perfect ground truth, we programmatically generate over 200K spatial QA pairs across 2.5K video trajectories spanning 1.2K unique scenes.
Key Findings
Finding 1: A minimal “3Q” mix is highly data-efficient
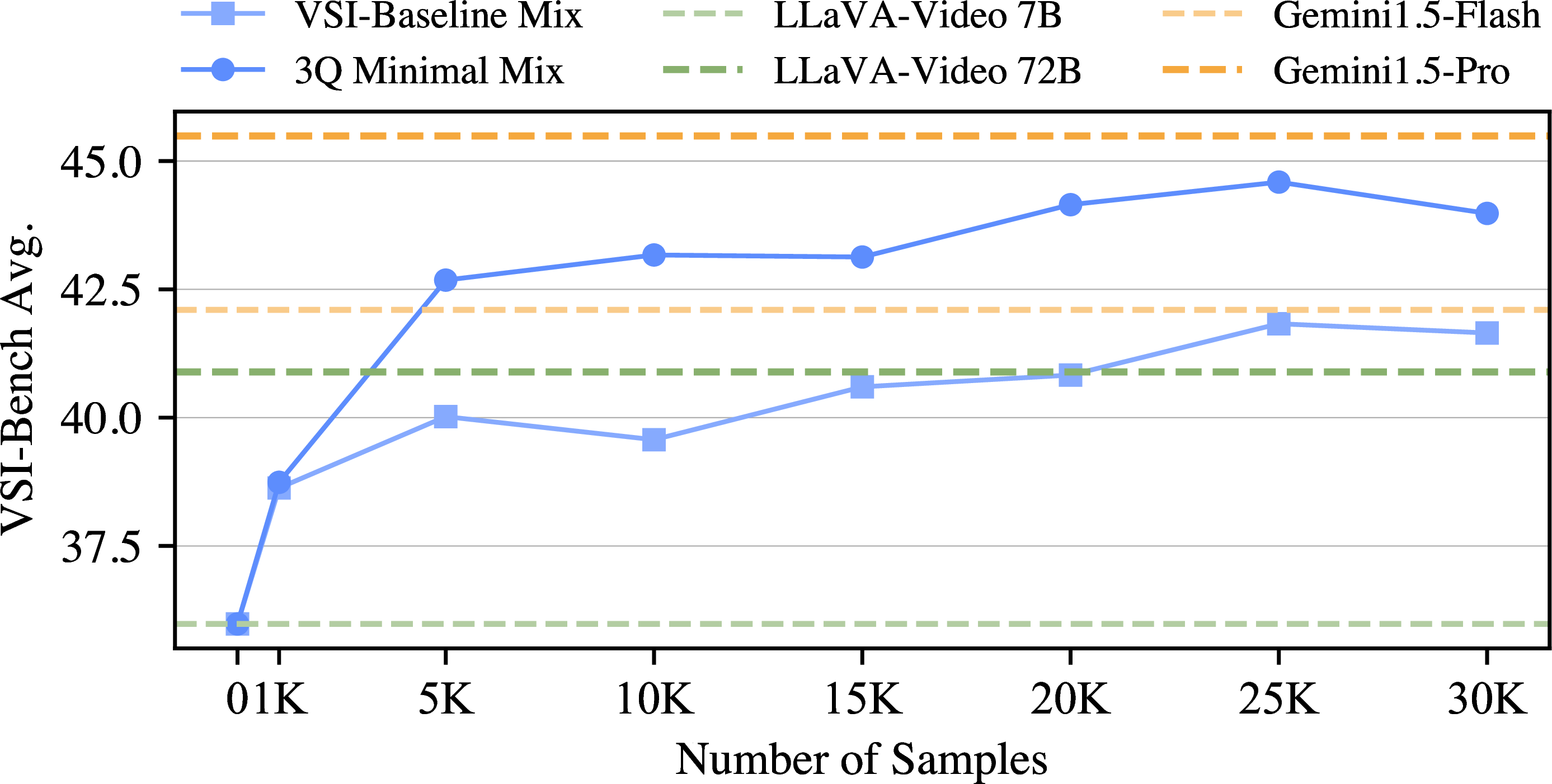
We hypothesized that a minimal set of complementary question types could be sufficient for developing spatial reasoning, without needing to mirror the full distribution of evaluation benchmarks. Through systematic experiments, we identify three question types that form an effective minimal training mix: Absolute Distance (measuring metric properties), Relative Direction (understanding perspective-dependent configurations), and Appearance Order (tracking temporal-spatial relationships).
This “3Q Minimal Mix” consistently outperforms the comprehensive “VSI-Baseline Mix” across all data scales (Figure 5). The result demonstrates that high-quality spatial annotations enable remarkably data-efficient learning—targeted supervision on core spatial dimensions proves more effective than comprehensive coverage.
Finding 2: SIMS-V training enables spatial skills competitive with proprietary models
Training with just 25K SIMS-V examples enables LLaVA-Video-7B to develop spatial reasoning capabilities competitive with large proprietary models. The approach yields +8.4% gains on VSI-Bench, with the resulting model (44.4%) surpassing both GPT-4o (34.0%) and the much larger LLaVA-Video-72B baseline (41.2%), nearly matching Gemini-1.5 Pro (45.4%).
The learned skills are particularly strong in the categories emphasized during training: spatiotemporal reasoning (appearance order: +26.4%) and metric measurement (absolute distance: +20.0%). This demonstrates that SIMS-V training enables effective sim-to-real transfer—spatial capabilities learned from simulated indoor scenes generalize to diverse real-world video content despite the substantial domain gap.
| Model | Average | Numerical Answer | Multiple-Choice | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Macro | Num | MC | Abs Dst | Obj Sz | Rm Sz | Obj Ct | Rel Dst | Rel Dir | Rt Pln | App Ord | |
| Statistics | |||||||||||
| Chance Level (Random) | — | — | 28.6 | — | — | — | — | 25.0 | 36.1 | 28.3 | 25.0 |
| Chance Level (Freq.) | 34.0 | 39.3 | 31.7 | 32.0 | 29.9 | 33.1 | 62.1 | 25.1 | 47.9 | 28.4 | 25.2 |
| Proprietary Models | |||||||||||
| GPT-4o | 34.0 | 33.4 | 34.6 | 5.3 | 43.8 | 38.2 | 46.2 | 37.0 | 41.3 | 31.5 | 28.5 |
| Gemini-1.5 Flash | 42.1 | 47.1 | 37.0 | 30.8 | 53.5 | 54.4 | 49.8 | 37.7 | 41.0 | 31.5 | 37.8 |
| Gemini-1.5 Pro | 45.4 | 48.7 | 42.1 | 30.9 | 64.1 | 43.6 | 56.2 | 51.3 | 46.3 | 36.0 | 34.6 |
| Gemini-2.5 Pro | 51.5 | 46.5 | 56.5 | 34.9 | 64.3 | 42.8 | 43.8 | 61.1 | 47.8 | 45.9 | 71.3 |
| Open-Source Models | |||||||||||
| LLaVA-Video 72B | 41.2 | 42.4 | 40.0 | 24.5 | 56.5 | 37.0 | 51.4 | 41.7 | 36.1 | 33.0 | 49.2 |
| LLaVA-Video 7B | 36.0 | 34.0 | 38.0 | 15.2 | 46.9 | 24.1 | 49.7 | 44.1 | 42.4 | 33.5 | 31.9 |
| + 25k SIMS-V 3Q | 44.4 | 40.3 | 48.6 | 35.2 | 41.2 | 38.1 | 46.5 | 53.8 | 47.3 | 35.1 | 58.3 |
| Δ Improvement | +8.4 | +6.3 | +10.7 | +20.0 | -5.7 | +14.0 | -3.2 | +9.7 | +4.9 | +1.6 | +26.4 |
| LLaVA-OneVision 72B | 40.9 | 42.5 | 39.3 | 25.2 | 57.0 | 41.8 | 46.1 | 42.8 | 34.9 | 32.0 | 47.6 |
| LLaVA-OneVision 7B | 35.0 | 34.7 | 35.3 | 14.8 | 47.6 | 23.1 | 53.2 | 43.4 | 38.4 | 31.4 | 27.8 |
| + 25k SIMS-V 3Q | 40.4 | 39.1 | 41.8 | 31.2 | 44.9 | 29.1 | 51.0 | 44.4 | 45.1 | 28.9 | 48.9 |
| Δ Improvement | +5.4 | +4.4 | +6.6 | +16.4 | -2.7 | +6.0 | -2.2 | +1.0 | +6.7 | -2.5 | +21.1 |
Finding 3: Learned skills transfer to diverse spatial tasks
To verify that spatial-focused training does not degrade general capabilities, we evaluated our model on diverse benchmarks beyond VSI-Bench. The results demonstrate robust generalization: our approach maintains stable performance on general video understanding tasks (VideoMME, EgoSchema) while showing strong positive transfer to new spatial domains.
Notably, spatial concepts learned from simulated indoor environments transfer effectively to embodied reasoning in real homes (OpenEQA: +8.6%) and outdoor real-world images (MMRealWorld: +4.5%). This cross-domain transfer suggests that our training develops fundamental spatial reasoning capabilities rather than overfitting to simulation artifacts.
| Model | VSI-B | VSI-BDeb. | OpenEQA | MME.RWlite | EgoSchema | VideoMME |
|---|---|---|---|---|---|---|
| Proprietary Models | ||||||
| GPT-4o | 34.0 | — | — | — | — | 71.9 |
| Gemini-1.5-Pro | 45.4 | 40.1 | — | — | 72.2 | 75.0 |
| Gemini-2.5 Pro | 51.5 | 49.1 | — | — | — | — |
| Open-Source Models | ||||||
| LLaVA-Video 72B | 41.2 | 36.8 | 43.8 | 36.0 | 66.7 | 68.8 |
| LLaVA-OneVision 72B | 40.9 | 35.6 | 43.0 | 48.2 | 62.8 | 66.7 |
| InternVL2.5 8B | 34.6 | 24.9 | — | — | 50.6 | 64.2 |
| Qwen-VL-2.5 7B | 33.5 | 29.6 | — | — | 65.0 | 65.1 |
| LLaVA-Video 7B | 36.0 | 30.7 | 34.6 | 35.2 | 56.9 | 63.3 |
| + 25k SIMS-V 3Q | 44.4 | 38.4 | 43.2 | 39.7 | 59.1 | 63.1 |
| Δ Improvement | +8.4 | +7.7 | +8.6 | +4.5 | +2.2 | -0.2 |
| LLaVA-OneVision 7B | 35.0 | 28.5 | 42.1 | 48.6 | 60.8 | 58.3 |
| + 25k SIMS-V 3Q | 40.4 | 33.9 | 42.2 | 49.7 | 60.5 | 59.0 |
| Δ Improvement | +5.4 | +5.4 | +0.1 | +1.1 | -0.3 | +0.7 |
Citation
If you find our work useful, please consider citing:
@article{brown2025simsv,
title = { {SIMS-V}: Simulated Instruction-Tuning for Spatial Video Understanding },
author = { Brown, Ellis and Ray, Arijit and Krishna, Ranjay and Girshick, Ross and Fergus, Rob and Xie, Saining },
journal = { arXiv preprint },
year = { 2025 }
}